Overview
A personal project I built in my free time to retain and expand my DevOps and platform engineering knowledge. The platform runs on a heavy WordPress stack featuring BuddyBoss Platform, LearnDash, and Elementor Pro plugins known for their resource intensity. I built a production-ready infrastructure with automated deployment pipelines, multi-tier caching, and performance optimizations to keep my skills sharp while exploring modern tooling and practices.
Tech Stack
Backend & Application
- PHP 8.3
- WordPress 6.8.3
- MariaDB 11.2
- WP-CLI
- BuddyBoss Platform Pro
- LearnDash LMS
- Elementor Pro
Infrastructure & DevOps
- Docker & Docker Compose
- Nginx
- GitHub Actions
- Ansible Playbooks
- Ubuntu 24.04 LTS
- DigitalOcean
Performance & Caching
- OPcache
- Redis(Object Cache)
- Nginx FastCGI Cache
Security & Monitoring
- New Relic Infra and PHP Agent
- New Relic Logging and Alerts
- UFW Firewall/Fail2ban
- SSL/TLS Encryption
- Automated Backups
- Health Checks
Architecture
The infrastructure spans four environments: local development with Docker Compose, and three deployed environments (dev, staging, production) on DigitalOcean managed by Ansible. GitHub Actions handles automated CI/CD with branch-based deployments. Cloudflare sits at the edge for DNS and CDN, while the origin server runs Nginx, PHP-FPM, MariaDB, and Redis.
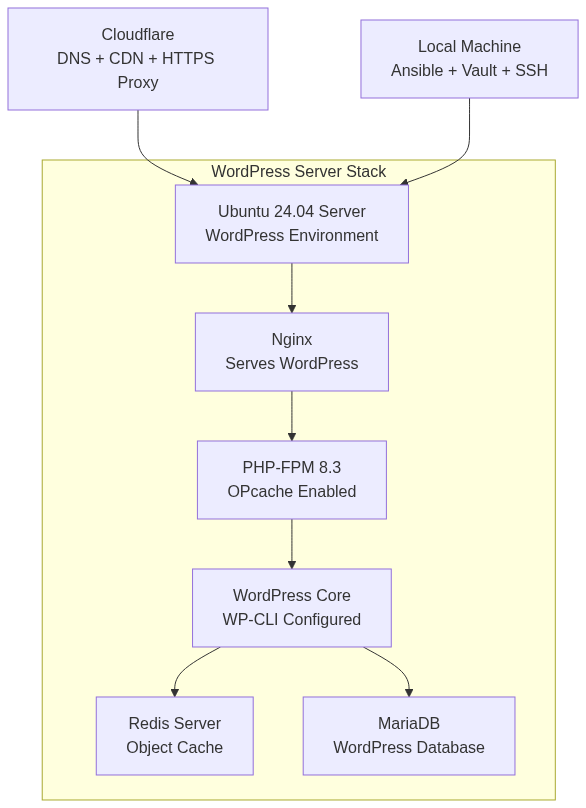
Infrastructure provisioning is fully automated with Ansible playbooks. A single playbook handles all environments by loading environment-specific variables, deploying the full stack (Nginx, PHP, MariaDB, Redis), configuring SSL certificates, and setting up security measures. This reduces deployment time and eliminates manual configuration errors.
Implementation, Challenges & Solutions
Key challenges I addressed while building the deployment pipeline, infrastructure automation, and performance optimizations for this resource-heavy WordPress stack.
1. Deployment Inefficiency
The Challenge
- Manual FTP deployments introduced human error and inconsistency
- File overwrites occurred without coordination between developers
- Production failures had no audit trail to identify what changed or when
- Rollback procedures were slow and unreliable
The Solution
- Built automated CI/CD pipeline using GitHub Actions
- Implemented branch-based deployment routing (dev, staging, production)
- Established Git-based version control with complete change history
2. Inconsistent Environment Behavior
The Challenge
- Code functioned correctly locally but failed in production
- Development environments ran different PHP and database versions than production
- Environment parity could not be guaranteed across dev, staging, and production
- Local testing produced unreliable results
The Solution
- Containerized the entire stack with Docker
- Enforced identical PHP and database versions across all environments
- Implemented Docker Compose for consistent local development
3. Performance During Traffic Spikes in Load Tests
The Challenge
- Server failures occurred during traffic spikes
- Database received excessive repetitive queries
- PHP recompiled identical content on every page load
- Site performance degraded under load
The Solution
- Cloudflare edge caching to serve static assets from geographically distributed nodes
- Nginx FastCGI cache to serve pre-rendered HTML, bypassing PHP and database
- Redis object cache to store database query results in memory
4. Testing on Stale Data
The Challenge
- Production bugs could not be reproduced in development or staging
- Test environments contained outdated data from months prior
- Stale datasets failed to represent actual production conditions
- Debugging required guesswork due to unrealistic test data
The Solution
- Built automated data synchronization script
- Implemented on-demand production data pulls
- Automated sanitization of sensitive information (PII, payment data)
- Established refresh process for development and staging environments
5. Runnin Without Monitoring
The Challenge
- Site outages were only detected through user reports
- Server resource usage and performance metrics were invisible
- Resource exhaustion could not be predicted before occurrence
- Issues escalated to full outages before detection
The Solution
- Deployed New Relic for comprehensive application and infrastructure monitoring
- Configured alerts at 80% thresholds for CPU, memory, and disk usage
- Implemented slow query tracking for database performance analysis
- Established error tracking with transaction-level debugging data
- Built real-time metrics dashboard for proactive monitoring
6. WordPress, Themes, and Plugin Update Pitfalls
The Challenge
- Admin dashboard updates introduced breaking changes without testing
- Update history was not tracked or documented
- Untested updates broke plugin compatibility in production
- Premium plugins lacked consistent version tracking and deployment
The Solution
- Built JSON package manifest as the single source of truth
- Defined all package versions in a Git-tracked manifest file
- Automated installation of exact versions through CI/CD pipeline
- Established version-controlled update management with full history
Results & Impact
Overall Achievement: Transformed a standard WordPress installation into an enterprise-grade platform capable of handling high traffic with sub-second page loads, and zero-downtime deployments while maintaining security best practices and developer productivity.